La bibliothèque JavaTM 1.0 |
|
|
|||
|
|
La gestion des fichiers |
![]()
Gestion des
entrées-sorties
Manipulation des fichiers
Gestion des flux de données
Accès à un flux de
données en lecture
Accès à un flux de
données en écriture
Gestion de l'accès
aléatoire aux fichiers
Ce chapitre décrit le package java.io de Java 1.0 qui rassemble les classes permettant de manipuler les fichiers et de gérer les entrées-sorties.
En observant la hiérarchie des classes de Java, vous serez peut-être étonné par le nombre de classes dévolues à la gestion des entrées-sorties (package java.io), et particulièrement celles de gestion des flux de données (stream). Ne vous inquiétez pas : une fois que vous aurez cerner le principe de fonctionnement de la gestion des flux de données, vous verrez que toutes les classes dérivant des classes InputStream et OutputStream s'utilisent de manière intuitive.
Mode d'accès aux données
Comme dans la plupart des langages informatiques, Java permet de manipuler les fichiers soit en accès par flux de données (Stream), soit en accès aléatoire (Random access) :
Ce système permet d'accéder à toute sorte de sources de données comme :
Quel est l'intérêt d'utiliser un flux de données pour
accéder à une chaîne de caractères ou à
un tableau d'octets, alors qu'il sera impossible d'accéder aux données
dans un ordre quelconque ?
La programmation orientée objet utilisée par Java permet de
manipuler les données entrantes ou sortantes avec les mêmes
classes, quelque soit le type de source de données : Pour lire les
données d'un flux vous utilisez les méthodes des classes InputStream,
FilterInputStream ou de ses classes
dérivées, et pour écrire dans un flux de données,
vous utilisez les méthodes des classes OutputStream,
FilterOutputStream ou de ses
classes dérivées.
Grâce à ceci, si vous créez une méthode qui effectue
des traitements sur des données provenant d'un flux, elle acceptera
n'importe quelle source de données, qu'elle soit en mémoire,
dans un fichier ou sur Internet.
|
|
Contrairement au C où il existe des fonctions différentes suivant le type de source de données (comme scanf (), fscanf (), sscanf ()), Java permet d'accéder aux différents types de flux de données par les mêmes méthodes. |
|
|
En C, la différence entre les deux types d'accès
par flux de données (fonctions f... () de stdio.h)
et à accès aléatoire (open (), read
(), ...) n'apparaît pas toujours de manière évidente.
En effet, les méthodes ftell () et fseek ()
permettent de se déplacer à une position quelconque
dans un fichier, ce qui rend possible l'accès aléatoire
! |
Les exceptions en Java permettent de programmer
de manière plus simple et surtout plus maintenable une séquence
d'instructions devant effectuer des entrées/sorties. Ce type de programme
effectue habituellement un grand nombre de contrôles puisqu'il faut
vérifier à chaque accès à un flux de données
ou un fichier si tout s'est bien déroulé. Une programmation
n'utilisant pas les exceptions est donc truffée de contrôles
après chaque instruction, ce qui en réduit la lisibilité.
En Java, la plupart des méthodes d'entrée/sortie déclenche
une exception de classe IOException
ou de ses dérivées EOFException,
FileNotFoundException,
InterruptedIOException
ou UTFDataFormatException.
Par exemple, une méthode qui va effectuer une lecture à l'intérieur
d'un fichier respectera généralement le schéma suivant
:
import java.io.*;
class Classe1
{
void lireFichier (String fichier)
{
try
{
// Suite d'instructions accédant au fichier et
// ne s'occupant pas de la gestion des erreurs
// Tentative d'ouvrir un fichier
// Lecture dans le fichier
}
catch (FileNotFoundException e)
{
// Exception déclenchée si le fichier n'existe pas
}
catch (IOException e)
{
// Exception déclenchée si un autre problème survient
// pendant l'accès au fichier
}
finally
{
// Le bloc finally est toujours exécuté ce qui permet d'être sûr
// que la fermeture du fichier sera effectuée
try
{
// Fermeture du fichier si le fichier a été ouvert
}
catch (IOException e)
{
// Exception déclenchée si un problème survient pendant la fermeture
}
}
}
}
Java permet de manipuler les fichiers situés sur le système local (par opposition à ceux auquel on accède via une URL), grâce à l'interface FilenameFilter et les classes File et FileDescriptor. On peut ajouter à cette liste la classe java.awt.FileDialog, qui permet de choisir interactivement un fichier avec une boite de dialogue.
Cette interface est utilisée pour permettre d'accepter ou de rejeter un fichier issu d'une liste. Une instance d'une classe implémentant cette interface est requise par les méthodes list () de la classe File et setFilenameFilter () de la classe FileDialog.
Méthode
public boolean accept (File dir, String name)Cette méthode doit renvoyer true si le fichier name se trouvant dans le répertoire dir est accepté.
Cette classe est utilisée pour représenter un chemin d'accès au système de fichiers local et effectuer des opérations sur celui-ci (autorisation d'accès en lecture/écriture, liste des fichiers d'un répertoire,...). Ce chemin d'accès peut désigner un fichier ou un répertoire.
Les méthodes de cette classe peuvent éventuellement déclencher une exception SecurityException, si le gestionnaire de sécurité actif leur interdit d'être exécutée. Les applets fonctionnant dans un navigateur empêchent généralement notamment tout accès au système de fichiers local donc n'imaginez pas une applet qui puisse accéder aux fichiers du système dans ce contexte.
La description des chemins d'accès (séparateurs, description des disques,...) utilise les conventions du système sur lequel est exécutée la Machine Virtuelle.Champs
public static final String separator public static final char separatorCharLa chaîne ou le caractère utilisé comme séparateur de fichier (égal généralement à / ou \).
public static final String pathSeparator public static final char pathSeparatorCharLa chaîne ou le caractère utilisé comme séparateur de plusieurs chemins d'accès (égal généralement à ; ou :).
Constructeurs
public File (String path)Construit une instance de la classe File, à partir d'un chemin d'accès path pouvant être absolu ou relatif au répertoire courant. path peut représenter un répertoire ou un fichier suivant l'utilisation que vous voulez faire de cette nouvelle instance.
public File (String dir, String name) public File (File dir, String name)Ces constructeurs permettent de créer une instance de la classe File, à partir d'un répertoire dir (chemin d'accès absolu ou relatif au répertoire courant), et d'un nom de fichier ou de répertoire name accessible à partir du répertoire dir.
Méthodes
public String getName ()Renvoie le nom du fichier ou du répertoire d'un chemin d'accès.
public String getPath ()Renvoie le chemin d'accès d'un objet de classe File.
public String getAbsolutePath ()Renvoie le chemin d'accès absolu.
public String getParent ()Renvoie le chemin d'accès du répertoire parent au chemin d'accès de l'objet de classe File, ou null s'il n'existe pas.
public boolean exists () throws SecurityException public boolean isFile () throws SecurityException public boolean isDirectory () throws SecurityException public boolean isAbsolute ()Ces méthodes renvoient true, si le chemin d'accès existe, s'il correspond à un fichier ou à un répertoire, ou si le chemin d'accès est absolu.
public boolean canRead () throws SecurityException public boolean canWrite () throws SecurityExceptionCes méthodes renvoient true, si le chemin d'accès est accessible en lecture ou en écriture.
public long lastModified () throws SecurityExceptionRenvoie la date de dernière modification du fichier. Cette date n'étant pas exprimé dans la même échelle que celle utilisée par la classe Date, elle ne peut être utilisée que pour comparer des dates de différents fichiers.
public long length () throws SecurityExceptionRenvoie la taille du chemin d'accès représentant un fichier.
public boolean delete () throws SecurityException public boolean renameTo (File dest) throws SecurityExceptionCes méthodes permettent de supprimer ou de renommer un chemin d'accès, et renvoient true si l'opération s'est effectuée correctement.
public boolean mkdir () throws SecurityException public boolean mkdirs () throws SecurityExceptionCes méthodes permettent de créer le répertoire ou les répertoires représentés par le chemin d'accès et renvoient true si l'opération s'est effectuée correctement.
public String [ ] list () throws SecurityException public String [ ] list (FilenameFilter filter) throws SecurityExceptionCes méthodes renvoient un tableau de chaînes de caractères dont les éléments sont les fichiers et les répertoires contenus dans le répertoire représenté par un chemin d'accès. Les répertoires . et .. sont exclus de cette liste.
La seconde méthode permet d'appliquer le filtre filter pour ne récupérer que les fichiers et les répertoires autorisés par la méthode accept () de la classe de l'objet filter implémentant l'interface FilenameFilter.public int hashCode () public boolean equals (Object obj) public String toString ()Ces méthodes outrepassent celles de la classe Object, pour renvoyer un code de hash, comparer un chemin d'accès à un objet ou renvoyer une chaîne de caractères égale au chemin d'accès.
Cette classe final représente un descripteur de fichier. Une instance de cette classe permet de manipuler un fichier ouvert ou l'entrée et les sorties standards.
Les méthodes getFD () des classes FileInputStream, FileOutputStream et RandomAccessFile permettent d'obtenir une instance de la classe FileDescriptor et les champs static in, out et err permettant de manipuler l'entrée standard, la sortie standard et la sortie standard d'erreurs sont de cette classe.Champs
public static final FileDescriptor in public static final FileDescriptor out public static final FileDescriptor errCes champs représentent l'entrée standard, la sortie standard ou la sortie standard des erreurs. Les champs de même nom de la classe System sont construits à partir de ces champs.
Vous pouvez les utiliser pour accéder à l'entrée et les sorties standards avec d'autres classes de gestion des flux de données.Constructeur
public FileDescriptor ()Méthodes
public boolean valid ()
En Java, les classes dévolues aux flux de données permettent d'accéder aux données soit en lecture grâce aux classes qui dérivent de la classe abstract InputStream, soit en écriture grâce aux classes qui dérivent de la classe abstract OutputStream.
A chaque type de flux de données (fichier, chaîne de caractères, tableau d'octets, pipeline) correspond une classe permettant de le manipuler, mais il existe aussi un ensemble de classes de filtres dérivées des classes abstract FilterInputStream et FilterOutputStream qui peuvent s'utiliser ensemble pour simplifier ou optimiser l'accès aux flux.
L'accès en lecture à un flux de données s'effectue grâce aux classes qui dérivent de la classe InputStream. Ces classes se divisent en deux catégories :
La création d'une instance d'une de ces classes permet d'accéder
sous forme d'un flux à la source de données à laquelle
elle est dédiée. En particulier, la création d'un objet
de classe FileInputStream permet
d'ouvrir un fichier et d'en lire le contenu.
En regardant les constructeurs de ces classes vous verrez qu'ils prennent
en paramètre une instance de la classe représentant le type
de sources de données qu'il manipule, comme le résume le tableau
suivant :
| Classes |
Paramètres des constructeurs |
|
|
|
|
|
|
|
|
|
Une fois que vous avez créé une instance d'une de ces classes, vous pouvez appeler les méthodes de la classe InputStream, puisque toutes ces classes en héritent, comme dans l'application suivante qui permet d'écrire sur la sortie standard les n premiers caractères d'un fichier. Recopiez-la dans un fichier LectureFichier.java, que vous compilez avec l'instruction javac LectureFichier.java pour ensuite l'exécuter avec java ou Java Runner, grâce à l'instruction java LectureFichier nomFichier nombreCaracteres (par exemple java LectureFichier LectureFichier.java 100) :
import java.io.*;
public class LectureFichier
{
// Méthode lancée à l'appel de l'instruction :
// java LectureFichier nomFichier nombreCaracteres
public static void main (String [ ] args)
{
try
{
// Ouverture du fichier passé en paramètre dans la ligne de commande
InputStream fluxFichier = new FileInputStream (args [0]);
// Lecture des n premiers octets du fichier. n est passé en paramètre
byte contenuFichier [ ] = new byte [Integer.parseInt (args [1])];
fluxFichier.read (contenuFichier);
// Ecriture sur la sortie standard des octets lus convertis
// en une chaîne de caractères
System.out.println (new String (contenuFichier, 0));
// Fermeture du fichier
fluxFichier.close ();
}
catch (IOException e)
{
// Exception déclenchée si un problème survient pendant l'accès au fichier
System.out.println (e);
}
}
}
L'accès aux trois autres types de sources de données restantes (l'entrée standard, les sockets et un fichier via une URL) s'effectue différemment :
Cette architecture est très pratique : elle permet de créer par exemple des méthodes de traitement qui peuvent accéder à n'importe quel flux de données via une référence de classe InputStream qui leur est passé en paramètre. Mais les méthodes de lecture de cette classe paraissent d'un intérêt très limité : elle permettent de lire un ou plusieurs octets, c'est tout ! C'est là qu'intervient la seconde catégorie de classes dérivant de InputStream, afin d'enrichir les méthodes de lecture des flux de données.
Contrairement aux classes dédiées à un type de source
de données, les constructeurs de ces classes prennent tous en paramètre
un objet de classe InputStream, qui
est le flux de données sur lequel elles font une lecture avant d'effectuer
des traitements supplémentaires. La classe InputStream étant
la super classe de toutes les classes d'accès aux flux de données,
vous pouvez donc passer en paramètre une instance de n'importe quelle
classe qui en dérive.
Grâce à ce système vous pouvez utiliser n'importe quel
filtre sur une source de données, et même cumuler les filtres
les uns derrière les autres, comme le montre le schéma suivant
:
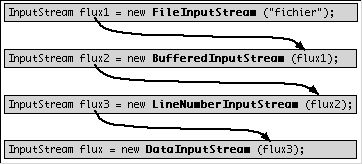
L'application suivante utilise ce schéma de filtres pour numéroter les lignes lues dans un fichier. Recopiez la dans un fichier NumerotationLigne.java, que vous compilez avec l'instruction javac NumerotationLigne.java pour ensuite l'exécuter avec java ou Java Runner, grâce à l'instruction java NumerotationLigne nomFichier (par exemple java NumerotationLigne NumerotationLigne.java) :
import java.io.*;
public class NumerotationLigne
{
// Méthode lancée à l'appel de l'instruction :
// java LectureFichier nomFichier
public static void main (String [ ] args)
{
try
{
// Ouverture du fichier passé en paramètre dans la ligne de commande
// avec un filtre utilisant un buffer
InputStream fluxFichier = new BufferedInputStream (
new FileInputStream (args [0]));
// Numérotation des lignes
numeroterLigne (fluxFichier);
fluxFichier.close ();
}
catch (IOException e)
{
// Exception déclenchée si un problème survient pendant l'accès au fichier
System.out.println (e);
}
}
public static void numeroterLigne (InputStream flux) throws IOException
{
// Création d'un filtre de décompte des lignes
LineNumberInputStream fluxLignes = new LineNumberInputStream (flux);
// Ajout d'un filtre pour lire de manière plus pratique les caractères
DataInputStream fluxLecture = new DataInputStream (fluxLignes);
// Lecture des lignes du flux jusqu'à la fin du flux
String ligne;
for (ligne = fluxLecture.readLine ();
ligne != null;
ligne = fluxLecture.readLine ())
// Ecriture sur la sortie standard de la ligne lue avec son numéro de ligne
System.out.println (String.valueOf (fluxLignes.getLineNumber ())
+ " : " + ligne);
}
}
En poursuivant dans cette logique, il est simple de créer et d'utiliser vos propres filtres sur des flux de données en dérivant vos nouvelles classes de la classe FilterInputStream ou d'une de ses classes dérivées.
Cette classe abstract est la super classe de toutes les classes qui permettent d'accéder à d'un flux de données en lecture (voir aussi le paragraphe précédent).
public abstract int read () throws IOException
Lit un octet dans le flux de données. Renvoie -1 si la fin est atteinte.
public int read (byte [ ] tab) throws IOException
Lit tab.length octets dans le tableau tab. Si la fin est atteinte pendant la lecture, tab est remplit avec les octets lus. Renvoie le nombre d'octets lus ou -1 si la fin est atteinte.
public int read (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
Lit length octets dans le tableau tab, en le remplissant à partir de l'indice offset. Si la fin est atteinte pendant la lecture, tab est remplit avec les octets lus. Renvoie le nombre d'octets lus ou -1 si la fin est atteinte.
public long skip (long n) throws IOException
Saute n octets plus loin dans la lecture du flux de données. Renvoie le nombre d'octets effectivement sautés.
public int available () throws IOException
Renvoie le nombre d'octets que les méthodes read () peuvent actuellement lire sans bloquer le thread courant.
public void close () throws IOException
Ferme l'accès au flux de données.
public synchronized void mark (int readlimit)
Marque la position courante dans le flux de données, pour qu'un appel à la méthode reset () provoque un retour en arrière à cette position. readlimit permet de préciser le nombre d'octets maximum que l'on peut lire avant que la marque soit invalide, c'est-à-dire la taille maximum du retour en arrière qu'il est possible de faire.
public synchronized void reset () throws IOException
Repositionne la position courante dans le flux de données sur la dernière marque positionnée par la méthode mark (). Si aucune marque n'a été positionnée ou si la marque est invalide, une exception IOException est déclenchée.
public boolean markSupported ()
Renvoie true si le flux de données autorise l'utilisation des méthodes mark () et reset ().
Applications LectureFichier, NumerotationLigne, ConcatenationFichiers et EchoServeur.
Cette classe qui dérive de la classe InputStream permet d'ouvrir et d'accéder à un fichier en lecture, sous forme de flux de données.
public FileInputStream (String path) throws SecurityException, FileNotFoundException public FileInputStream (File file) throws SecurityException, FileNotFoundException
Ces constructeurs permettent de créer une instance de classe FileInputStream à partir du chemin d'accès à un fichier path ou d'une instance de classe File.
public FileInputStream (FileDescriptor fdObj) throws SecurityException
Construit une instance de classe FileInputStream à partir d'un descripteur de fichier fdObj.
public int read () throws IOException public int read (byte [ ] tab) throws IOException public int read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public long skip (long n) throws IOException public int available () throws IOException public void close () throws IOException
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à la lecture d'un fichier.
public final FileDescriptor getFD () throws IOException
Permet d'obtenir un descripteur de fichier.
protected void finalize () throws IOException
Méthode de la classe Object outrepassée pour que le fichier ouvert à la création d'une instance de la classe FileInputStream soit fermé avant que le Garbage Collector n'intervienne pour détruire cet objet. Le moment où intervient le Garbage Collector n'étant généralement pas prévisible, il vaut mieux fermer soi-même le fichier avec la méthode close (), pour éviter d'en bloquer l'accès à d'autres programmes.
Applications LectureFichier, NumerotationLigne et ConcatenationFichiers.
Cette classe qui dérive de la classe InputStream permet d'accéder à une chaîne de caractères en lecture, sous forme de flux de données.
protected String buffer protected int pos protected int count
public StringBufferInputStream (String s)
Construit une instance de classe StringBufferInputStream à partir de la chaîne de caractères s.
public synchronized int read ()
public synchronized int read (byte [ ] tab, int offset, int length)
throws IndexOutOfBoundsException
public synchronized long skip (long n)
public synchronized int available ()
public synchronized void reset ()
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à l'accès à une chaîne de caractères.
Applet PaperBoardClient.
Cette classe qui dérive de la classe InputStream permet d'accéder à un tableau d'octets en lecture, sous forme de flux de données.
protected byte [ ] buf protected int pos protected int count
public ByteArrayInputStream (byte [ ] buf)
Construit une instance de classe ByteArrayInputStream à partir du tableau d'octets buf.
public ByteArrayInputStream (byte [ ] buf, int offset, int length)
Construit une instance de classe ByteArrayInputStream à partir du tableau d'octets buf, où length octets seront lus à partir de l'indice offset.
public synchronized int read () throws IndexOutOfBoundsException public synchronized int read (byte [ ] tab, int offset, int length) throws IndexOutOfBoundsException public synchronized long skip (long n) public synchronized int available () public synchronized void reset ()
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à l'accès à un tableau d'octets.
Cette classe qui dérive de la classe InputStream permet d'accéder à un pipeline en lecture, sous forme de flux de données.
public PipedInputStream () public PipedInputStream (PipedOutputStream src) throws IOException
public void connect (PipedOutputStream src) throws IOException
Crée une connexion avec la sortie du pipeline src.
public synchronized int read () throws IOException public synchronized int read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public void close () throws IOException
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à l'accès à un pipeline.
Cette classe qui dérive de la classe InputStream permet d'accéder en lecture à un ensemble de flux de données les uns après les autres.
public SequenceInputStream (InputStream s1, InputStream s2)
Construit une instance de classe SequenceInputStream à partir des flux de données s1 et s2. Les méthodes read () de cette classe liront le contenu des flux s1 et s2 l'un à la suite de l'autre, comme s'il forme un seul flux.
public SequenceInputStream (Enumeration e)
Construit une instance de classe SequenceInputStream à partir d'une énumération de flux de données e. Les méthodes read () de cette classe liront le contenu de tous les flux énumérés par e, comme s'il forme un seul flux. Chacun des objets énumérés par e doit donc être de classe InputStream ou d'une de ses classes dérivées.
public int read () throws IOException public int read (byte [ ] buf, int pos, int length) throws IOException, IndexOutOfBoundsException public void close () throws IOException
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à l'accès à un ensemble de flux de données.
Application ConcatenationFichiers.
Cette classe qui dérive de la classe InputStream est la super classe de toutes les classes utilisées pour filtrer la lecture d'un flux de données. Vous pouvez utiliser les classes BufferedInputStream, DataInputStream, LineNumberInputStream ou PushBackInputStream qui en dérivent mais aussi créer vos propres classes de filtre dérivant de cette classe.
protected InputStream in
Le flux de données sur lequel la lecture est faite. Utilisez ce champ dans vos classes dérivées pour lire des données sur le flux à filtrer.
protected FilterInputStream (InputStream in)
Le constructeur de cette classe est protected ce qui vous empêche de l'instancier (cette classe n'a de toute façon aucun effet sur le flux de données ). Il est utilisé par les classes dérivées.
public int read () throws IOException public int read (byte [ ] tab) throws IOException public int read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public long skip (long n) throws IOException public int available () throws IOException public void close () throws IOException public synchronized void mark (int readlimit) public synchronized void reset () throws IOException public boolean markSupported ()
Méthodes de la classe InputStream outrepassées pour qu'elles s'appliquent à l'accès à un flux de données filtré en lecture.
Voici un exemple d'une classe de filtre dérivée de FilterInputStream qui a pour effet de mettre en majuscule toutes les lettres qui sont lus sur un flux de données :
class ToUpperCaseInputStream extends FilterInputStream
{
// Constructeur : appel du constructeur de la super classe
public ToUpperCaseInputStream (InputStream flux)
{
super (flux);
}
public int read () throws IOException
{
// Lecture sur le flux d'un byte
int car = in.read ();
// Si la fin du fichier n'est pas atteinte et si le caractère
// lu est une minuscule renvoyer la majuscule correspondante
if ( car != -1
&& Character.isLowerCase ((char)car))
return Character.toUpperCase ((char)car);
return car;
}
public int read (byte tab [], int offset, int length) throws IOException
{
// Lecture sur le flux : read () renvoie le nombre d'octets lus
int nbreOctetsLus = in.read (tab, offset, length);
// Conversion de toutes les minuscules lues en majuscules
for (int i = 0; i < nbreOctetsLus; i++)
if (Character.isLowerCase ((char)tab [offset + i]))
tab [offset + i] = (byte)Character.toUpperCase ((char)tab [offset + i]);
return nbreOctetsLus;
}
}
Si dans l'application NumerotationLigne vous remplacez la ligne :
DataInputStream fluxLecture = new DataInputStream (fluxLignes);
par les lignes :
DataInputStream fluxLecture = new DataInputStream (
new ToUpperCaseInputStream (fluxLignes));
vous pourrez vous rendre compte du résultat. Bien sûr ce filtre ne peut s'appliquer qu'à des fichiers textes.
Cette classe qui dérive des classes FilterInputStream et InputStream permet de lire sur un flux de données en utilisant une zone mémoire tampon (buffer). Cette classe se charge de lire sur le flux de données un grande nombre d'octets qu'elle garde dans un buffer. Tous les appels à la méthode read () ultérieurs sur une instance de cette classe renvoient du coup le contenu de ce buffer tant qu'il y reste des octets à lire. Ceci évite de faire une lecture physique sur le flux de données à chaque appel de la méthode read () c'est pourquoi ce filtre est très souvent utilisé.
protected byte [ ] buf protected int count protected int pos protected int markpos protected int marklimit
public BufferedInputStream (InputStream in) public BufferedInputStream (InputStream in, int size)
Ces constructeurs permettent de créer une instance de la classe BufferedInputStream dont la lecture sera effectuée sur le flux de données in. size est la taille utilisée pour créer le buffer (égal à 2048 par défaut).
public synchronized int read () throws IOException public synchronized int read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public synchronized long skip (long n) throws IOException public synchronized int available () throws IOException public synchronized void mark (int readlimit) public synchronized void reset () throws IOException public boolean markSupported ()
Méthodes de la classe FilterInputStream outrepassées pour qu'elles s'appliquent à ce filtre.
Applications NumerotationLigne,
ConcatenationFichiers et PaperBoardServer.
Applet PaperBoardClient.
Cette interface implémentée par les classes DataInputStream et RandomAccessFile déclare un ensemble de méthodes qui permettent de lire à partir d'un flux de données ou d'un fichier des données de différents types : Soit un ensemble d'octets grâce aux méthodes readFully (), soit une donnée binaire représentant un type primitif Java, soit une chaîne de caractères.
public void readFully (byte [ ] tab) throws IOException
Cette méthode doit permettre de lire tab.length octets dans le tableau tab. Une exception EOFException est déclenchée si la fin du fichier est atteinte, et une exception IOException est déclenchée en cas d'autre erreur.
public void readFully (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
Cette méthode doit permettre de lire length octets dans le tableau tab, en le remplissant à partir de l'indice offset. Une exception EOFException est déclenchée si la fin du fichier est atteinte, et une exception IOException est déclenchée en cas d'autre erreur.
public boolean readBoolean () throws IOException public byte readByte () throws IOException public int readUnsignedByte () throws IOException public short readShort () throws IOException public int readUnsignedShort () throws IOException public char readChar () throws IOException public int readInt () throws IOException public long readLong () throws IOException public float readFloat () throws IOException public double readDouble () throws IOException
Ces méthodes doivent permettre de lire une valeur booléenne, un octet, un octet non signé (codé sur 8 bits et compris en 0 et 255), un short, un short non signé, un int, un long, un float ou un double. Une exception EOFException est déclenchée si la fin du fichier est atteinte, et une exception IOException est déclenchée en cas d'autre erreur.
public String readLine () throws IOException
Cette méthode doit permettre de lire tous les caractères jusqu'au premier symbole de retour à la ligne. Elle manipule des caractères codés sur 8 bits et non sur 16 bits (Unicode). Renvoie la chaîne de caractères lue sans le caractère de retour à la ligne à la fin, ou null si la fin du fichier est atteinte.
public String readUTF () throws IOException
Cette méthode doit permettre de lire une chaîne de caractères qui est codée au format UTF. Renvoie la chaîne de caractères lue ou null si la fin du fichier est atteinte.
public int skipBytes (int n) throws IOException
Cette méthode doit permettre de sauter n octets. Une exception EOFException est déclenchée si la fin du fichier est atteinte, et une exception IOException est déclenchée en cas d'autre erreur.
Cette classe qui dérive des classes FilterInputStream et InputStream implémente l'interface DataInput, ce qui permet de lire à partir d'un flux de données autres chose que des octets.
public DataInputStream (InputStream in)
Construit une instance de la classe DataInputStream dont la lecture sera effectuée sur le flux de données in.
public final void read (byte [ ] tab) throws IOException public final void read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException
Méthodes de la classe FilterInputStream outrepassées pour qu'elles s'appliquent à ce filtre.
public final void readFully (byte [ ] tab)
throws IOException
public final void readFully (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
public final boolean readBoolean () throws IOException
public final byte readByte () throws IOException
public final int readUnsignedByte () throws IOException
public final short readShort () throws IOException
public final int readUnsignedShort () throws IOException
public final char readChar () throws IOException
public final int readInt () throws IOException
public final long readLong () throws IOException
public final float readFloat () throws IOException
public final double readDouble () throws IOException
public final String readLine () throws IOException
public final String readUTF () throws IOException
public final static String readUTF (DataInput in) throws IOException
public final int skipBytes (int n) throws IOException
Implémentation des méthodes de l'interface DataInput.
Applications NumerotationLigne
et PaperBoardServer.
Applet PaperBoardClient.
Cette classe qui dérive des classes FilterInputStream et InputStream permet de compter le nombre de lignes lors de la lecture d'un flux de données. Une ligne se termine par le caractère '\n'. L'application NumerotationLigne utilise cette classe de filtre.
public LineNumberInputStream (InputStream in)
Construit une instance de la classe LineNumberInputStream dont la lecture sera effectuée sur le flux de données in. Le numéro de ligne est initialisé à 0.
public int read () throws IOException public int read (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public long skip (long n) throws IOException public int available () throws IOException public void mark (int readlimit) public void reset () throws IOException
Méthodes de la classe FilterInputStream outrepassées pour qu'elles s'appliquent à ce filtre.
public int getLineNumber () public void setLineNumber (int lineNumber)
Ces méthodes permettent d'interroger ou de modifier le numéro de ligne courant.
Application NumerotationLigne.
Cette classe qui dérive des classes FilterInputStream et InputStream permet de simuler un retour en arrière d'un octet pendant la lecture d'un flux de données. La méthode unread () qui est utilisée pour revenir en arrière d'un octet prend en paramètre l'octet à renvoyer à la lecture suivante. Cette classe est surtout utilisée pour les analyseurs lexicaux et syntaxiques.
protected int pushBack
public PushbackInputStream (InputStream in)
public int read () throws IOException public int read (byte [ ] bytes, int offset, int length) throws IOException, IndexOutOfBoundsException public int available () throws IOException public boolean markSupported ()
Méthodes de la classe FilterInputStream outrepassées pour qu'elles s'appliquent à ce filtre.
public void unread (int ch) throws IOException
Permet de simuler un retour en arrière d'un octet. L'octet ch est le prochain octet qui sera renvoyé par un appel à une méthode read (). Cette méthode déclenche une exception de classe IOException si deux appels à unread () sont effectués à la suite sans appel à une des méthodes read () entre temps.
Cette classe permet d'énumérer à partir d'un flux
de données un ensemble de sous-chaînes ou de nombres séparées
en spécifiant différents délimiteurs de manière
plus riche que la classe java.util.StringTokenizer.
Cette classe peut être utilisée par exemple pour écrire
un compilateur.
Seuls les caractères dont le code est compris entre 0 et
255 sont utilisables.
public static final int TT_EOF public static final int TT_EOL public static final int TT_NUMBER public static final int TT_WORD
Ces constantes représentent le type d'une sous-chaîne lue : la fin du flux de données, la fin d'une ligne, un nombre ou un mot.
public int ttype
Ce champ mémorise le type de la dernière sous-chaîne lue (avec pour valeur TT_EOF, TT_EOL, TT_NUMBER ou TT_WORD). Voir aussi la description des méthodes qui suivent.
public String sval public double nval
Ces champs mémorisent le dernier nombre (si ttype = TT_NUMBER) ou le dernier mot lu (si ttype = TT_WORD).
public StreamTokenizer (InputStream in)
Construit une instance de la classe StreamTokenizer avec comme flux de données d'entrée in.
public void wordChars (int low, int high)
Permet d'ajouter tous les caractères dont le code est compris entre low et high à l'ensemble des caractères utilisés pour construire un mot. La lecture d'un mot s'arrête quand un des caractères utilisés comme espace ou un caractère ordinaire sont lus. Quand un mot est lu, le champ ttype est égal à TT_WORD et le champ sval contient le mot lu.
public void whitespaceChars (int low, int high)
Permet d'ajouter tous les caractères dont le code est compris entre low et high à l'ensemble des caractères utilisés comme espace.
public void commentChar (int ch)
Permet d'ajouter le caractère de code ch à l'ensemble des caractères délimitant le début d'un commentaire de fin de ligne.
public void ordinaryChar (int ch) public void ordinaryChars (int low, int high)
Permet d'ajouter le caractère de code ch ou tous les caractères
dont le code est compris entre low et high à l'ensemble
des caractères ordinaires. Un caractère ordinaire n'appartient
ni à l'ensemble des caractères utilisés pour construire
un mot ou un nombre, ni à l'ensemble des caractères utilisés
comme espace ou comme délimiteurs de commentaire.
Quand un caractère ordinaire est lu, le champ ttype a pour
valeur ce caractère.
public void quoteChar (int ch)
Permet d'ajouter le caractère de code ch à l'ensemble des caractères utilisés pour entourer une chaîne de caractères constante. Quand une chaîne de caractères constante est lue, le champ ttype est égal au délimiteur et le champ sval contient la chaîne lue sans les délimiteurs.
public void parseNumbers ()
Permet de spécifier que les nombres doivent être lus en tant que tels, c'est-à-dire que l'appel de cette méthode mémorise que les chiffres 0 à 9, les caractères '.' et '-' appartiennent à l'ensemble des caractères utilisés pour construire un nombre. Quand un nombre est lu, le champ ttype est égal à TT_NUMBER et le champ nval contient le nombre lu.
public void resetSyntax ()
Remet à zéro la syntaxe définie avec les méthodes précédentes.
public void eolIsSignificant (boolean flag)
Permet de spécifier que les caractères de fin de ligne sont significatifs ou non. Si flag est égal à true, le champ ttype vaudra TT_EOL chaque fois qu'une fin de ligne est lue, sinon les caractères de fin de ligne seront considérés comme un espace.
public void slashStarComments (boolean flag)
Permet de spécifier si les commentaires Java /* ... */ sont significatifs ou non.
public void slashSlashComments (boolean flag)
Permet de spécifier si les commentaires Java de fin de ligne // ... sont significatifs ou non.
public void lowerCaseMode (boolean flag)
Permet de spécifier si tous les mots lus sont convertis en minuscules ou non.
public int nextToken () throws IOException
Lit dans le flux d'entrée la sous-chaîne suivante en respectant la syntaxe définie grâce aux méthodes précédentes. Renvoie la valeur du champ ttype.
public void pushBack ()
Permet de revenir d'une sous-chaîne en arrière une fois.
public int lineno ()
Renvoie le numéro de ligne courant.
public String toString ()
Méthode de la classe Object, outrepassée pour qu'elle renvoie une description de la dernière sous-chaîne lue.
Applet PaperBoardClient.
La création d'une instance d'une de ces classes permet d'accéder
sous forme d'un flux à la source de données à laquelle
elle est dédiée. En particulier, la création d'un objet
de classe FileOutputStream permet
d'ouvrir un fichier et d'y écrire.
En regardant les constructeurs de ces classes vous verrez qu'ils prennent
en paramètre une instance de la classe représentant le type
de sources de données qu'il manipule, comme le résume le tableau
suivant :
| Classes |
Paramètres des constructeurs |
|
|
|
|
|
Une fois que vous avez créé une instance d'une de ces classes,
vous pouvez appeler les méthodes de la classe OutputStream,
puisque toutes ces classes en héritent.
L'accès aux trois autres types de sources de données restantes
(les sorties standards, les sockets
et un fichier via une URL) s'effectue
différemment :
Comme pour la classe InputStream, les méthodes d'écriture de la classe OutputStream paraissent d'un intérêt très limité : elle permettent d'écrire un ou plusieurs octets, c'est pourquoi il existe aussi une seconde catégorie de classes dérivant de OutputStream, afin d'enrichir les méthodes d'écriture sur les flux de données.
Contrairement aux classes dédiées à un type de source de données, les constructeurs de ces classes prennent tous en paramètre un objet de classe OutputStream, qui est le flux de données sur lequel elles effectuent des traitements supplémentaires avant d'y écrire. La classe OutputStream étant la super classe de toutes les classes d'écriture sur les flux de données, vous pouvez donc passer en paramètre une instance de n'importe quelle classe qui en dérive.
L'application suivante utilise les classes FileInputStream, SequenceInputStream, FileOutputStream et BufferedOutputStream pour effectuer la concaténation de plusieurs fichiers dans un fichier destination. Recopiez la dans un fichier ConcatenationFichiers.java, que vous compilez avec l'instruction javac ConcatenationFichiers.java pour ensuite l'exécuter avec java ou Java Runner, grâce à l'instruction java ConcatenationFichiers nomFichier1 ... nomFichierN fichierDest (par exemple java ConcatenationFichiers ConcatenationFichiers.java NumerotationLigne.java resultat.java) :
import java.io.*;
import java.util.Vector;
public class ConcatenationFichiers
{
// Méthode lancée à l'appel de l'instruction :
// java ConcatenationFichiers nomFichier1 ... nomFichierN nomFichierDest
public static void main (String [ ] args)
{
try
{
Vector ensembleFichiers = new Vector ();
// Ajout à ensembleFichiers de tous les flux de données avec buffer
// correspondant à chaque fichier d'entrée passé en paramètres
// (sauf le dernier paramètre)
for (int i = 0; i < args.length - 1; i++)
ensembleFichiers.addElement (new BufferedInputStream (
new FileInputStream (args [i])));
// Création d'un ensemble de flux d'entrée
InputStream fluxEntree =
new SequenceInputStream (ensembleFichiers.elements ());
// Ouverture en écriture avec un buffer du fichier
// passé en dernier paramètre dans la ligne de commande
OutputStream fluxDestination =
new BufferedOutputStream (
new FileOutputStream (args [args.length -1]));
byte donnees [ ] = new byte [1000];
int nbreOctetsLus;
// Lecture puis écriture des données
while ((nbreOctetsLus = fluxEntree.read (donnees)) != -1)
fluxDestination.write (donnees, 0, nbreOctetsLus);
// Fermeture des flux
fluxDestination.close ();
fluxEntree.close ();
}
catch (IOException e)
{
// Exception déclenchée si un problème survient pendant l'accès aux fichiers
System.out.println (e);
}
}
}
Cette classe abstract est la super classe de toutes les classes qui permettent d'écrire sur un flux de données en lecture (voir aussi le paragraphe précédent).
public abstract void write (int b) throws IOException
Ecrit un octet sur le flux de données.
public void write (byte [ ] tab) throws IOException
Ecrit les octets du tableau tab sur le flux de données.
public void write (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
Ecrit length octets du tableau tab sur le flux de données, à partir de l'indice offset.
public void flush () throws IOException
Ecrit physiquement sur le flux de données quand une zone tampon (buffer) est utilisée.
public void close () throws IOException
Ferme l'accès au flux de données.
Application ConcatenationFichiers et EchoServeur.
Cette classe qui dérive de la classe OutputStream permet d'ouvrir un fichier et d'y écrire, sous forme de flux de données.
public FileOutputStream (String path) throws SecurityException, FileNotFoundException public FileOutputStream (File file) throws SecurityException, FileNotFoundException
Ces constructeurs permettent de créer une instance de classe FileOutputStream à partir du chemin d'accès à un fichier path ou d'une instance de classe File. Si le fichier n'existe pas il est créé.
public FileOutputStream (FileDescriptor fdObj) throws SecurityException
Construit une instance de classe FileInputStream à partir d'un descripteur de fichier fdObj.
public void write (int b) throws IOException public void write (byte [ ] tab) throws IOException public void write (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public void close () throws IOException
Méthodes de la classe OutputStream outrepassées pour qu'elles s'appliquent à l'écriture dans un fichier.
public final FileDescriptor getFD () throws IOException
Permet d'obtenir un descripteur de fichier.
protected void finalize () throws IOException
Méthode de la classe Object outrepassée pour que le fichier ouvert à la création d'une instance de la classe FileOutputStream soit fermé avant que le Garbage Collector n'intervienne pour détruire cet objet. Le moment où intervient le Garbage Collector n'étant généralement pas prévisible, il vaut mieux fermer soi-même le fichier avec la méthode close (), pour éviter d'en bloquer l'accès à d'autres programmes.
Application ConcatenationFichiers.
Cette classe qui dérive de la classe OutputStream permet d'accéder à un pipeline en écriture, sous forme de flux de données.
public PipedOutputStream (PipedInputStream snk) throws IOException public PipedOutputStream ()
public void connect (PipedInputStream snk) throws IOException
Crée une connexion avec l'entrée du pipeline snk.
public void write (int b) throws IOException public void write (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public void close () throws IOException
Méthodes de la classe OutputStream outrepassées pour qu'elles s'appliquent à l'écriture sur un pipeline.
Cette classe qui dérive de la classe OutputStream permet d'écrire dans un tableau d'octets, sous forme de flux de données. Ce tableau est créé par la classe et automatiquement agrandi s'il est plein.
protected byte [ ] buf protected int count
public ByteArrayOutputStream () public ByteArrayOutputStream (int size)
Ces constructeurs permettent de créer une instance de classe ByteArrayOutputStream, dont le tableau sera au minimum de size octets (égal à 32 par défaut).
public synchronized void write (int b)
public synchronized void write (byte [ ] tab, int offset, int length)
throws IndexOutOfBoundsException
Méthodes de la classe OutputStream outrepassées pour qu'elles s'appliquent à l'écriture dans un tableau d'octets.
public int size ()
Renvoie le nombre courant d'octets écrits dans le tableau.
public synchronized void reset ()
Remet l'index courant dans le tableau à 0 sans allouer un nouveau tableau.
public synchronized byte [ ] toByteArray ()
Renvoie un tableau d'octets copie des octets écrits dans le tableau interne.
public String toString ()
Méthode de la classe Object, outrepassée pour qu'elle renvoie les octets écrits dans le tableau sous forme de chaîne de caractères.
public String toString (int hibyte)
Renvoie les octets écrits dans le tableau sous forme de chaîne de caractères, dont chaque caractère Unicode a hibyte pour partie haute.
public synchronized void writeTo (OutputStream out) throws IOException
Ecrit sur le flux de données out les octets écrits dans le tableau.
Cette classe qui dérive de la classe OutputStream est la super classe de toutes les classes utilisées pour filtrer l'écriture sur un flux de données. Vous pouvez utiliser les classes BufferedOutputStream, DataOutputStream ou PrintStream qui en dérivent mais aussi créer vos propres classes de filtre dérivant de cette classe (voir aussi la classe ToUpperCaseInputStream comme exemple de filtre).
protected OutputStream out
public FilterOutputStream (OutputStream out)
public void write (int b) throws IOException public void write (byte [ ] tab) throws IOException public void write (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public void flush () throws IOException public void close () throws IOException
Méthodes de la classe OutputStream outrepassées pour qu'elles s'appliquent à l'accès à un flux de données filtré en écriture.
Cette classe qui dérive des classes FilterOutputStream et OutputStream permet d'écrire sur un flux de données en utilisant une zone mémoire tampon (buffer). Lors d'un appel à la méthodes write (), les octets sont stockés dans le buffer. Le buffer est écrit finalement sur le flux de données une fois qu'il est plein ou lors d'un appel à la méthode flush (). Ceci évite de faire une écriture physique sur le flux de données à chaque appel de la méthode write () c'est pourquoi ce filtre est très souvent utilisé.
protected byte [ ] buf protected int count
public BufferedOutputStream (OutputStream out) public BufferedOutputStream (OutputStream out, int size)
Ces constructeurs permettent de créer une instance de la classe BufferedOutputStream dont l'écriture sera effectuée sur le flux de données out. size est la taille utilisée pour créer le buffer (égal à 512 par défaut).
public synchronized void write (int b) throws IOException public synchronized void write (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public synchronized void flush () throws IOException
Méthodes de la classe FilterOutputStream outrepassées pour qu'elles s'appliquent à ce filtre.
Application ConcatenationFichiers
et PaperBoardServer.
Applet PaperBoardClient.
Cette interface implémentée par les classes DataOutputStream
et RandomAccessFile déclare
un ensemble de méthodes qui permettent d'écrire dans un flux
de données ou dans un fichier des données de différents
types : Soit un ensemble d'octets grâce aux méthodes write
(), soit une donnée binaire représentant un type
primitif Java, soit une chaîne de caractères.
Les données écrites grâce à ces méthodes
sont lisibles grâce aux méthodes de l'interface DataInput,
quelque soit le système sur lequel les données ont été
écrites. Le codage binaire des nombres étant souvent différemment
d'un système à l'autre, ceci permet de créer des flux
de données portables.
public void write (int b) throws IOException
Cette méthode doit permettre d'écrire un octet.
public void write (byte [ ] tab) throws IOException
Cette méthode doit permettre d'écrire les octets du tableau tab.
public void write (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
Cette méthode doit permettre d'écrire length octets du tableau tab, à partir de l'indice offset.
public void writeBoolean (boolean v) throws IOException public void writeByte (int v) throws IOException public void writeShort (int v) throws IOException public void writeChar (int v) throws IOException public void writeInt (int v) throws IOException public void writeLong (long v) throws IOException public void writeFloat (float v) throws IOException public void writeDouble (double v) throws IOException
Ces méthodes doivent permettre d'écrire une valeur booléenne, un octet, un short, un caractère Unicode, un int, un long, un float ou un double.
public void writeBytes (String s) throws IOException
Cette méthode doit permettre d'écrire la chaîne de caractères s. Elle écrit les caractères en les codant sur 8 bits et non sur 16 bits (Unicode).
public void writeChars (String s) throws IOException
Cette méthode doit permettre d'écrire la chaîne de caractères s, comme une suite de caractères Unicode.
public void writeUTF (String s) throws IOException
Cette méthode doit permettre d'écrire au format UTF la chaîne de caractères s.
Cette classe qui dérive des classes FilterOutputStream et OutputStream implémente l'interface DataOutput, ce qui permet d'écrire sur un flux de données autres chose que des octets.
protected int written
public DataOutputStream (OutputStream out)
Construit une instance de la classe DataOutputStream dont l'écriture sera effectuée sur le flux de données out.
public synchronized void write (int b) throws IOException public synchronized void write (byte [ ] tab, int offset, int length) throws IOException, IndexOutOfBoundsException public final void writeBoolean (boolean v) throws IOException public final void writeByte (int v) throws IOException public final void writeShort (int v) throws IOException public final void writeChar (int v) throws IOException public final void writeInt (int v) throws IOException public final void writeLong (long v) throws IOException public final void writeFloat (float v) throws IOException public final void writeDouble (double v) throws IOException public final void writeBytes (String s) throws IOException public final void writeChars (String s) throws IOException public final void writeUTF (String str) throws IOException
Implémentation des méthodes de l'interface DataOutput. La méthode write (byte [ ] tab) est implémentée par la classe FilterOutputStream.
public void flush () throws IOException
Méthodes de la classe FilterOutputStream outrepassées pour qu'elles s'appliquent à ce filtre.
public final int size ()
Renvoie le nombre d'octets écrits sur le flux de données depuis la création du filtre.
Cette classe qui dérive des classes FilterOutputStream
et OutputStream permet d'écrire
au format texte les types primitifs Java. Elle est très souvent utilisée
via le champ System.out qui
est justement de classe PrintStream.
Contrairement aux méthodes des autres classes écrivant sur
un flux de données, les méthodes de la classe PrintStream
ne déclenchent jamais d'exceptions de classe IOException.
Si une erreur survient pendant l'écriture sur le flux de données,
un champ private prend la valeur true et la méthode
checkError () renvoie cette valeur. Ce système qui peut
paraître peu contraignant pour l'utilisateur de la classe PrintStream
et laisser passer des erreurs plus facilement, comporte malgré tout
un avantage majeur : il permet par exemple d'écrire sur la sortie
standard avec le champ System.out
sans être obligé d'utiliser un bloc try ... catch.
public PrintStream (OutputStream out) public PrintStream (OutputStream out, boolean autoflush)
Ces constructeurs permettent de créer une instance de la classe PrintStream dont l'écriture sera effectuée sur le flux de données out. autoflush permet de préciser si un appel à la méthode flush () doit être effectué à chaque retour à la ligne (égal à false par défaut).
public void write (int b)
public void write (byte [ ] tab, int offset, int length)
throws IndexOutOfBoundsException
public void flush ()
public void close ()
Méthodes de la classe FilterOutputStream outrepassées pour qu'elles s'appliquent à ce filtre.
public boolean checkError ()
Appelle la méthode flush () et renvoie true si une erreur est survenue pendant un appel aux autres méthodes de cette classe.
public void print (Object obj) public synchronized void print (String s) public synchronized void print (char [ ] tab) public void print (boolean b) public void print (char c) public void print (int i) public void print (long l) public void print (float f) public void print (double d)
Ces méthodes permettent d'écrire au format texte un objet, une chaîne de caractère, un tableau de caractères, une valeur booléenne, un caractère, un int, un long, un float ou un double, sur le flux de données. Le texte écrit pour l'objet obj est la chaîne de caractère renvoyée par l'appel obj.toString ().
public synchronized void println (Object obj) public synchronized void println (String s) public synchronized void println (char [ ] tab) public synchronized void println (boolean b) public synchronized void println (char c) public synchronized void println (int i) public synchronized void println (long l) public synchronized void println (float f) public synchronized void println (double d)
Ces méthodes effectuent les mêmes opérations que le groupe précédent, puis écrivent un retour à la ligne sur le flux de données.
public void println ()
Ecrit un retour à la ligne sur le flux de données.
|
|
Cette classe offre l'équivalent des fonctions printf
() du C, mais ne comporte pas toute la richesse des formats
de données disponibles avec printf (). |
Les applications Banque,
LectureFichier, NumerotationLigne,
ConcatenationFichiers, TestExpression
et PaperBoardServer utilisent
le champ System.out et la méthode
println ().
Applet PaperBoardClient.
Java fournit la classe RandomAccessFile pour accéder aléatoirement au contenu d'un fichier en lecture ou en écriture (voir aussi le début de ce chapitre).
public RandomAccessFile (String path, String mode)
throws SecurityException, IOException, IllegalArgumentException
public RandomAccessFile (File file, String mode)
throws SecurityException, IOException, IllegalArgumentException
Ces constructeurs permettent d'ouvrir le fichier représenté
par son chemin d'accès path ou par une instance de la classe
File. Si mode est égal à "rw" (read/write)
il est possible d'écrire ou de lire dans le fichier ouvert et le
fichier est créé s'il n'existe pas.
Si mode est égal à "r" (read), le fichier
est accessible uniquement en lecture et par conséquent l'utilisation
des méthodes d'écriture write...() de cette classe
déclenchera une exception de classe IOException.
public final FileDescriptor getFD () throws IOException
Permet d'obtenir un descripteur de fichier.
public long getFilePointer () throws IOException
Renvoie la position courante dans le fichier.
public void seek (long pos) throws IOException
Déplace la position courante en pos dans le fichier.
public long length () throws IOException
Renvoie la taille courante du fichier.
public void close () throws IOException
Ferme l'accès au fichier.
public abstract int read () throws IOException
Lit un octet dans le flux de données. Renvoie -1 si la fin est atteinte.
public int read (byte [ ] tab) throws IOException
Lit tab.length octets dans le tableau tab. Si la fin est atteinte pendant la lecture, tab est remplit avec les octets lus. Renvoie le nombre d'octets lus ou -1 si la fin est atteinte.
public int read (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
Lit length octets dans le tableau tab, en le remplissant à partir de l'indice offset. Si la fin est atteinte pendant la lecture, tab est remplit avec les octets lus. Renvoie le nombre d'octets lus ou -1 si la fin est atteinte.
public int skipBytes (int n) throws IOException
Méthode de l'interface DataInput implémentée pour qu'elle déplace de n octets la position courante dans le fichier. n peut être positif ou négatif (pour revenir en arrière). Renvoie n.
public final void readFully (byte [ ] tab) throws IOException
public final void readFully (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
public final boolean readBoolean () throws IOException
public final byte readByte () throws IOException
public final int readUnsignedByte () throws IOException
public final short readShort () throws IOException
public final int readUnsignedShort () throws IOException
public final char readChar () throws IOException
public final int readInt () throws IOException
public final long readLong () throws IOException
public final float readFloat () throws IOException
public final double readDouble () throws IOException
public final String readLine () throws IOException
public final String readUTF () throws IOException
Implémentation des autres méthodes de l'interface DataInput.
public void write (int b) throws IOException
public void write (byte [ ] tab) throws IOException
public void write (byte [ ] tab, int offset, int length)
throws IOException, IndexOutOfBoundsException
public final void writeBoolean (boolean v) throws IOException
public final void writeByte (int v) throws IOException
public final void writeShort (int v) throws IOException
public final void writeChar (int v) throws IOException
public final void writeInt (int v) throws IOException
public final void writeLong (long v) throws IOException
public final void writeFloat (float v) throws IOException
public final void writeDouble (double v) throws IOException
public final void writeBytes (String s) throws IOException
public final void writeChars (String s) throws IOException
public final void writeUTF (String str) throws IOException
Implémentation des méthodes de l'interface DataOutput.
|
||||